Transform maps are powerful tools widely used to process data from import (import set) to ServiceNow tables. After creation, they can be reused, so they are a very good fit for External Data Sources such as Excel, CSV, XML, HTTP / FTP, and JDBC.
In this blog post, I will describe how to start with IRE and bring CMDB transformations to the next level in terms of quality and data integrity. In future blog posts, I aim to focus on specific use cases, such as using it with Flow Designer or non-CMDB tables.
What is IRE?
IRE is a centralized framework for identification and reconciliation processes across different data sources. Before inserting the data into the CMDB, identification rules, reconciliation rules, and IRE data source rule are applied in order to:
- Prevent duplication of CI’s by uniquely identifying them.
- Reconciliate CI attributes by administering the data sources that can write to CMDB.
It is already used in applications such as Discovery and Service Mapping. It can also be applied to REST and Scriptable APIs for third-party data sources.
It is advantageous when multiple data sources, such as Event Management, ImportSets, manual entry, and Discovery, are used.
IRE is processing the payloads to correctly maintain the Configuration Management Database - creating new CIs or updating existing ones.
Before we go into detail about how to start with IRE and apply it to your transform map, let’s dig a little bit deeper to understand what is going on behind the scenes, let’s take a look at the process.
IRE Process Overview

Source: diagram was based on ServiceNow community/support materials
The most important thing about IRE Process is that the payload is generated by the sources calling the IRE engine. This payload is being validated. If there are errors, they are conveniently logged so that we know exactly what has happened.
If there are no payload errors, Identification Rules are applied. After that, there are 3 scenarios:
- No match is found - a record will be created.
- Exactly one match is found - a record will be updated.
- Multiple records are found - the oldest record will be updated, and the rest will be marked as duplicates. A De-Duplicate Task will be created.
Isn’t that convenient? IRE efficiently works for even huge imports. Processing time will probably be much shorter than transforms without it, given that the engine will cover most, if not all, of the validation.
There are a lot of resources available on how the IRE API works, The Cloud People can help to pinpoint where it would be most beneficial to use it in your environment and how to implement it successfully. Let’s focus on why to use it and how to implement it into your transform map.
Why do you need IRE?
So why would you use it? In short terms - to avoid CI duplication, for data integrity.
When using multiple data sources such as transform maps, third-party integrations, Service Mapping, or Discovery, there is a high risk that the CMDB data might receive undesired updates and not be up to date or contain relevant information.
A centralized framework such as IRE helps ensure that the right information is inserted into the right records without spending a lot of time on writing field map scripts, setting coalesce, and validation.
The bigger the import, the bigger the gains. Correct information on CMDB is vital, regardless of the industry your company is in.
IRE becomes useful when you want to import records to multiple CMDB classes.
It is also a very efficient way to validate and process imports. ServiceNow created the API, which is well documented. The methods used are designed to be maintainable and fast.
With the IRE, there is no need to think about the coalesce. You can set all the identification rules in one place, for all the data sources or separately for each one of them.
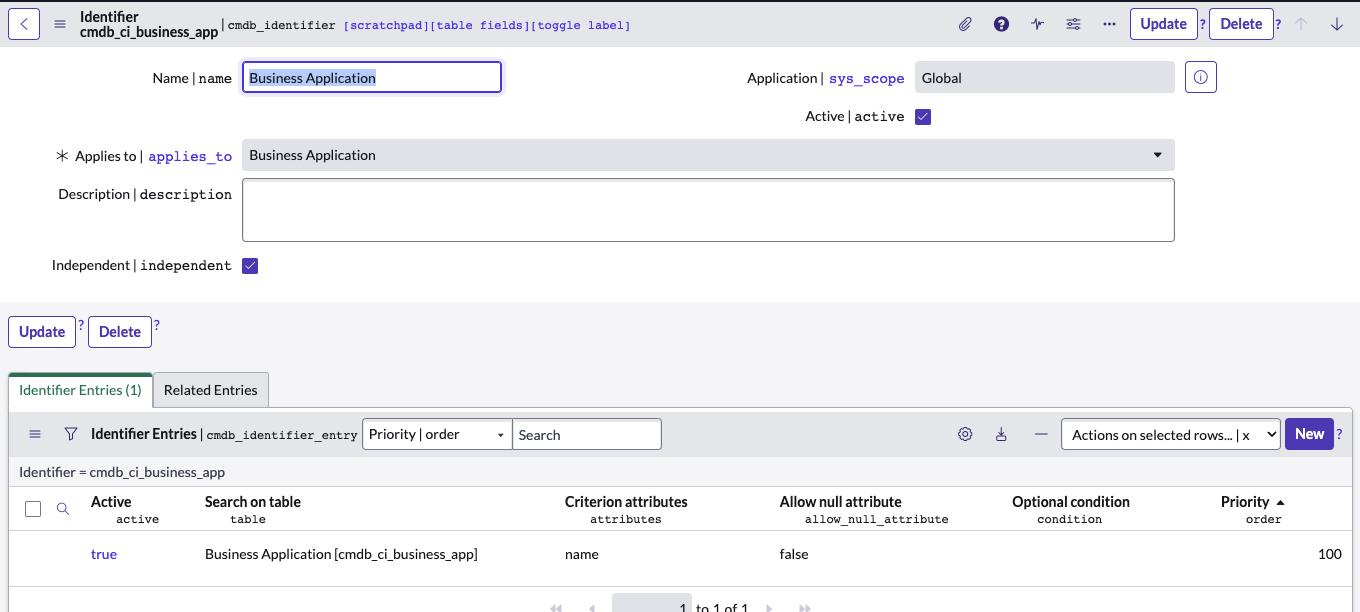
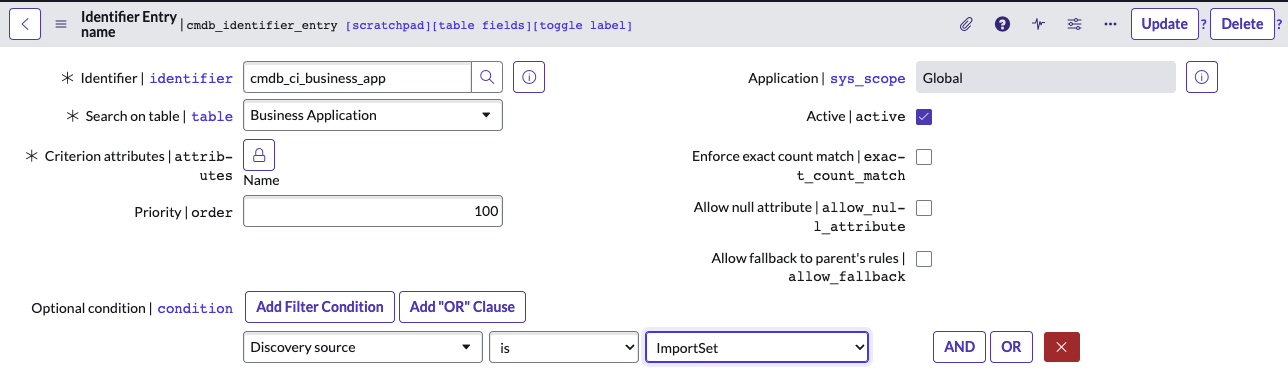
Identifiers specify what attributes make CI unique. This Identifier Entry would ensure that during the import of Business Applications with the use of ImportSet, the name of the Business App will be the main criteria to create/update or skip the record. Other Identifiers can be added for other data sources and/or with different order of processing. This is a very nice way of managing multiple CMDB data sources.
How to apply the IRE to the transform map?
- Install the plugin: Configuration Management For Scoped Apps CMDB (Plugin id: com.snc.cmdb.scoped). It ensures scoped apps access to Identification Engine APIs.
- Create Identifier: a set of rules for a class that the URE uses to determine if a CI should be created, updated, or skipped.
- Create Reconciliation Rules: determine what data sources should be prioritized. This prevents less reliable data sources from updating fields in a class.
- Create onBefore script (it should run as the last one from all onBefore scripts).
IRE onBefore script - example

What to keep in mind?
There are a few things you should consider when using the IRE:
- Review the Identification/Reconciliation properties. If class upgrade/downgrade/switch properties are enabled, the CI class can change and that could lead to data loss. Fortunately, this can be set globally for all the IRE as presented in the image below.

Additionally, enabling/disabling class upgrade/downgrade/switch can be set via a script, according to the import requirements.
- Run script option in the transform map will be redundant:
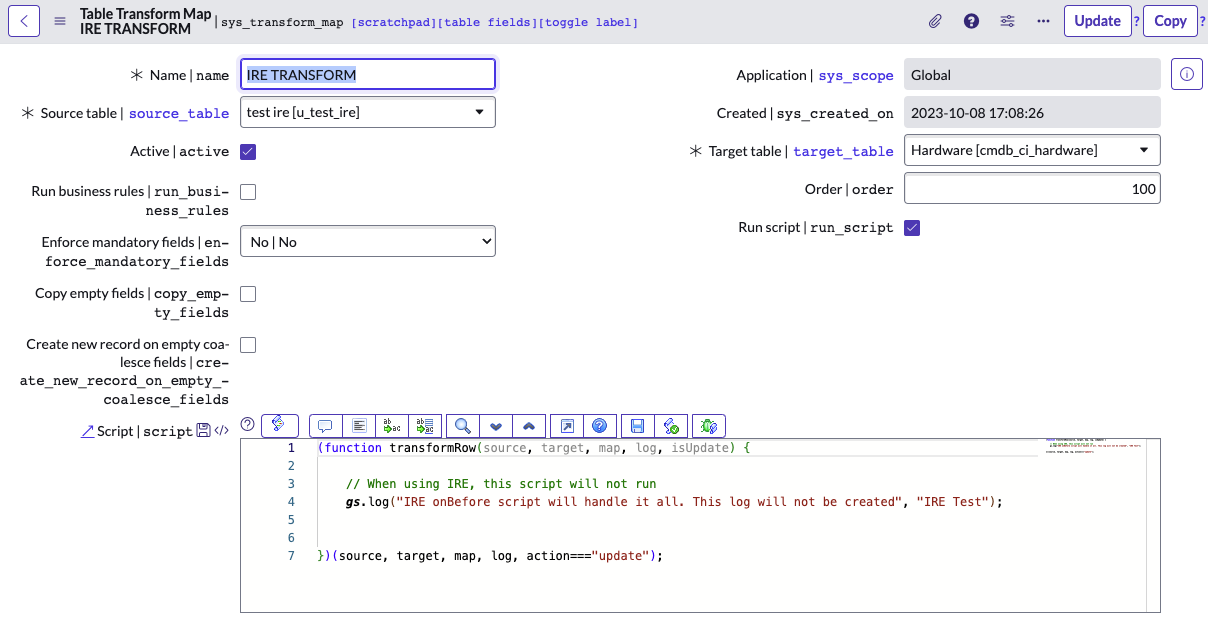
- Coalesce does not matter with IRE, onBefore script will trigger methods that check Identification and Reconciliation rules that will be applied instead.
- Set the Data Source in the onBefore script, e.g.: “ImportSet”.
- Transform History will show that all the processed records were ignored. This is because all the Identification and Reconciliation are triggered in the onBefore transform scripts, which then set the records to be ignored to prevent double-processing.
- Relevant information about the payload can be found in the system logs.
Key takeaways:
The identification and Reconciliation engine is a centralized framework with the API that processes the payload to update/create or skip records. It is mainly designed for CMDB data, but it can also be used with non-CMDB tables.
Setting it up is relatively easy and could enhance the data import into your CMDB. In The Cloud People, we have consultants who can help you define the process and implement it successfully. Reach out to us if you have any questions!
Useful links: